
Ti sei mai chiesto come i motori di ricerca come Google e Bing raccolgono tutti i dati che presentano nei loro risultati di ricerca? È perché i motori di ricerca indicizzano tutte le pagine nei loro archivi in modo che possano restituire i risultati più rilevanti in base alle query. I web crawler consentono ai motori di ricerca di gestire questo processo.
Questo articolo mette in evidenza aspetti importanti di cos’è la scansione, perché è importante, come funziona, applicazioni ed esempi.
Cosa significa scansione di un sito web
La scansione del Web è il processo di indicizzazione dei dati nelle pagine Web utilizzando un programma o uno script automatizzato. Questi script o programmi automatizzati sono conosciuti con più nomi, inclusi web crawler, spider, spider bot e spesso abbreviati in crawler.
I web crawler copiano le pagine per l’elaborazione da parte di un motore di ricerca, che indicizza le pagine scaricate in modo che gli utenti possano cercare in modo più efficiente. L’obiettivo di un crawler è sapere di cosa trattano le pagine web. Ciò consente agli utenti di recuperare qualsiasi informazione su una o più pagine quando necessario.
Perché la scansione del web è importante?
Grazie alla rivoluzione digitale, la quantità totale di dati sul web è aumentata. Nel 2013, IBM ha dichiarato che il 90% dei dati mondiali era stato creato solo nei 2 anni precedenti e che continuiamo a raddoppiare il tasso di produzione dei dati ogni 2 anni. Tuttavia, quasi il 90% dei dati non è strutturato e la scansione del Web è fondamentale per indicizzare tutti questi dati non strutturati affinché i motori di ricerca forniscano risultati pertinenti.
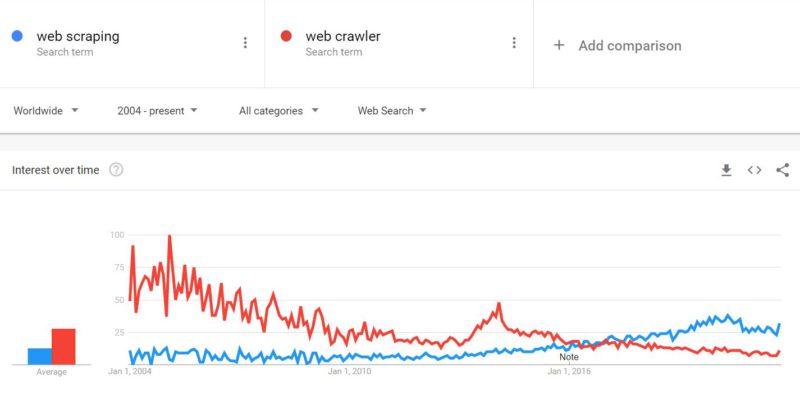
Secondo i dati di Google, l’interesse per l’argomento del web crawler è diminuito dal 2004. Tuttavia, allo stesso tempo, l’interesse per il web scraping ha superato l’interesse per il web crawling. Si possono fare varie interpretazioni, alcune sono:
- Il crescente interesse per l’ analisi e il processo decisionale basato sui dati sono i principali fattori che spingono le aziende a investire nello scraping.
- La scansione eseguita dai motori di ricerca non è più un argomento di crescente interesse poiché lo hanno fatto dai primi anni 2000
- L’industria dei motori di ricerca è un settore maturo dominato da Google e Baidu, quindi poche aziende hanno bisogno di creare crawler.
Come funziona un web crawler?
I web crawler iniziano il loro processo di scansione scaricando il file robot.txt del sito web. Il file include mappe del sito che elencano gli URL che il motore di ricerca può scansionare. Una volta che i web crawler iniziano a eseguire la scansione di una pagina, scoprono nuove pagine tramite i collegamenti. Questi crawler aggiungono gli URL appena scoperti alla coda di scansione in modo che possano essere scansionati in un secondo momento. Grazie a queste tecniche, i web crawler possono indicizzare ogni singola pagina collegata ad altre.
Poiché le pagine cambiano regolarmente, è anche importante identificare la frequenza con cui i motori di ricerca dovrebbero eseguirne la scansione. I crawler dei motori di ricerca utilizzano diversi algoritmi per decidere fattori come la frequenza con cui eseguire nuovamente la scansione di una pagina esistente e quante pagine di un sito devono essere indicizzate.
Cosa sono le applicazioni di scansione web?
La scansione del Web è comunemente utilizzata per indicizzare le pagine per i motori di ricerca. Ciò consente ai motori di ricerca di fornire risultati pertinenti per le query. Il web scraping viene utilizzato anche per descrivere il web scraping , l’estrazione di dati strutturati da pagine web e il web scraping ha numerose applicazioni .
Quali sono gli esempi di scansione web?
Tutti i motori di ricerca devono avere un crawler, alcuni esempi sono:
- Amazonbot è un web crawler di Amazon per l’identificazione dei contenuti web e il rilevamento dei backlink.
- Baiduspider per Baidu
- Bingbot per il motore di ricerca Bing di Microsoft
- DuckDuckBot per DuckDuckGo
- Exabot per il motore di ricerca francese Exalead
- Googlebot per Google
- Yahoo! Slurp per Yahoo
- Yandex Bot per Yandex
Comandi per i web crawler
Puoi utilizzare gli standard di esclusione dei robot per indicare ai crawler quali pagine del tuo sito Web devono essere indicizzate e quali no. Queste istruzioni vengono inserite in un file chiamato robots.txt o possono anche essere comunicate tramite meta tag nell’intestazione HTML. Tieni presente, tuttavia, che i crawler non seguono sempre queste istruzioni.
Ecco una breve storia della prima generazione di web crawler.
1. Ragno RBSE – sviluppato e utilizzato dal programma Repository Based Software Engineering (RBSE) finanziato dalla NASA nell’anno 1994, presso l’ Università di Houston , Clear Lake. È stato costruito da David Eichmann della NASA utilizzando i linguaggi Oracle, C e wais. Lo scopo principale di questo crawler era l’indicizzazione e l’origine delle statistiche. Al momento della creazione di questo crawler, la dimensione del Web era di circa 100.000 pagine Web.
2. WebCrawler – creato da Brian Pinkerton della Università di Washington e lanciato il 20 aprile 1994 , WebCrawler è stato il primo motore di ricerca che è stato alimentato da un web crawler. Secondo Wikipedia , WebCrawler è stato il primo motore di ricerca web a fornire la ricerca full-text.
3. Archive.org – Internet Archive, noto anche come The Wayback Machine , utilizzava Heritrix come suo web crawler per archiviare l’intero web. Scritto in Java, ha una licenza software gratuita accessibile tramite un browser web o tramite uno strumento a riga di comando. Vale anche la pena notare che Heritrix non è l’unico crawler utilizzato nella creazione di Internet Archive. In effetti, la maggior parte dei dati è stata donata da Alexa Internet, che esegue la scansione dei dati per i propri scopi con un crawler chiamato ia_archiver.
Crawler di seconda generazione per il Web
I crawler di seconda generazione sono a) crawler mirati o b) crawler su larga scala. I crawler mirati erano crawler specifici del sito, personalizzati e riposizionabili come SPHINX e Mercator. I fornitori di motori di ricerca come Google, Lycos ed Excite hanno sviluppato crawler in grado di eseguire la scansione e l’indicizzazione dei dati su scala globale.




